Machine Learning
Nachdem sich die beiden Teilbereiche Elektro und Leerfahrt schon im Projekt etabliert hatten, tat sich durch Machine Learning (ML) ein dritter Themenschwerpunkt auf. Dieser ist an und für sich schon interessant, gerade in Anbetracht der zunehmenden Verwendung von entsprechenden ML-Algorithmen im Bereich von Data Science. Daher wollten auch wir als Projekt untersuchen, wie gut wir dies mit unseren Carsharing Daten kombinieren können.
Aber auch die mögliche Kombination mit den anderen beiden Themenbereichen ist ein relevanter Aspekt. Dies lässt sich durch die Verwendung von ML-Algorithmen in Online-Algorithmen für die Probleme der anderen beiden Themen erreichen. Dies bietet uns direkt die Möglichkeit, das Wissen der Projektgruppen zu kombinieren und die Performanz der Elektro- oder Leerfahrtproblematik in der Praxis zu analysieren.
Wir haben uns also zunächst mit verschiedenen konkreten ML-Algorithmen und deren Funktionsweise beschäftigt und dann mit diesem Wissen bestimmte Fragestellungen bezüglich unserer Daten möglichst gut gelöst und evaluiert. Anschließend ist durch die Zusammenarbeit mit der Leerfahrtsgruppe ein Online-Algorithmus entstanden, der ein von uns entworfenes ML-Modell verwendet.
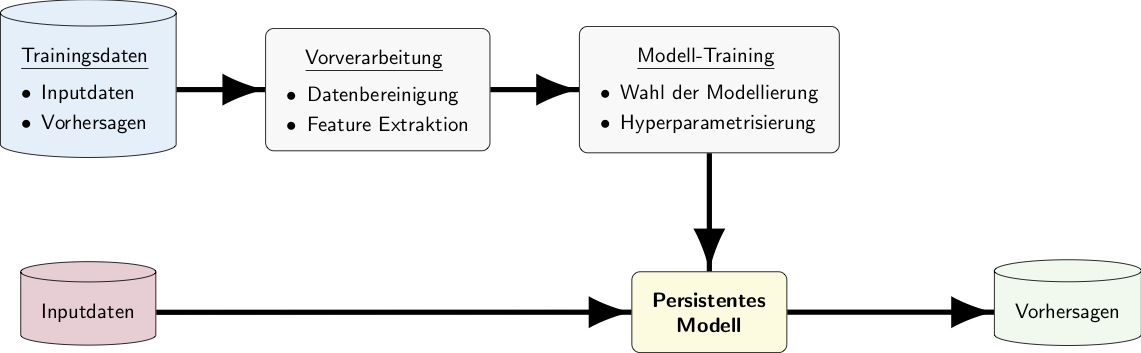
Trainingsdaten werden vorverarbeitet und dem Machine-Learning-Algorithmus zum Training übergeben.
Das trainierte Modell kann dann Vorhersagen treffen.
Forschungsfragen
- Bedarf an Stationen: Lohnt sich eine Leerfahrt zu einer anderen Station? Wie hoch wird der Bedarf dort sein?
- Absagewahrscheinlichkeiten: Welcher Kunde wird die gebuchte Fahrt antreten? Wer wird wahrscheinlich stornieren?
Trainingsdaten
Zwei primäre Datenquellen wurden zur Bearbeitung der Forschungsfragen herangezogen:
- Taxis: Die NYC Taxi & Limousine Commission, die Aufsichtsbehörde für Taxis in New York City, stellt Daten zu Taxifahrten bereit. Diese können kostenlos aus dem Netz heruntergeladen werden. Kombiniert wurden die Taxifahrten mit Daten zu gesetzlichen Feiertagen sowie Wetteraufzeichnungen der betreffenden Zeiträume.
- Carsharing: Von unserem Praxispartner cambio Mobilitätsservice GmbH & Co KG mit Sitz in Bremen erhielten wir reale Carsharing-Buchungsdaten.
Implementierung
Drei Machine-Learning-Ansätze wurden im Projekt näher betrachtet:
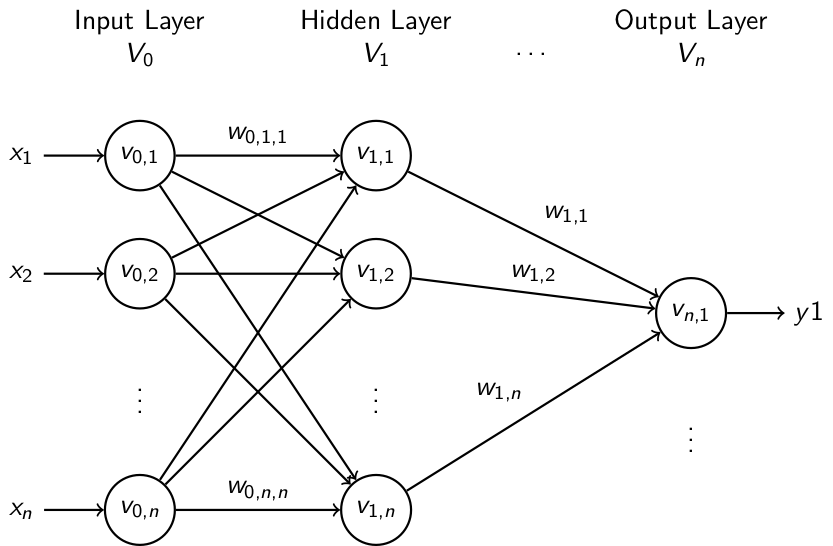
- Künstliche neuronale Netze
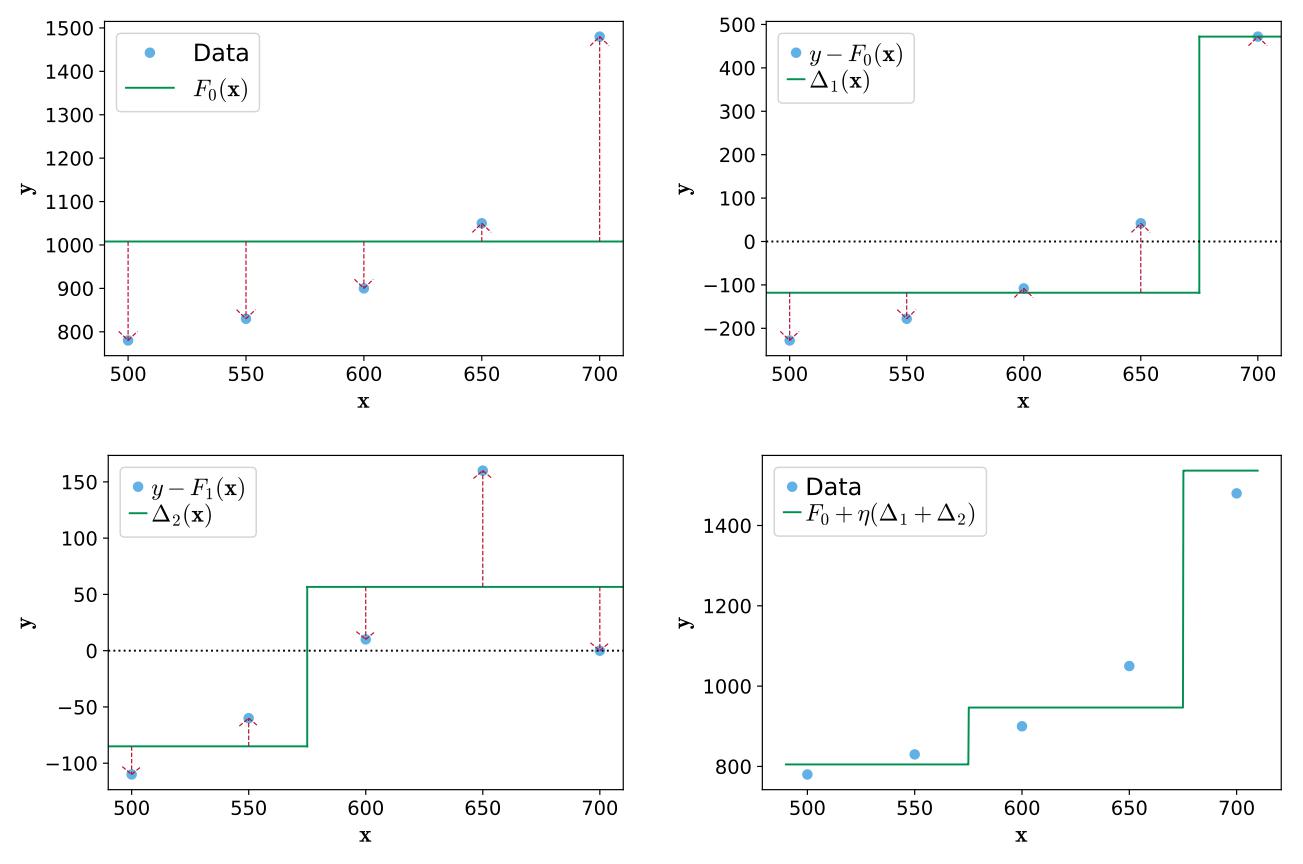
- Gradient Boosting
- Support Vector Regression
 |
 |
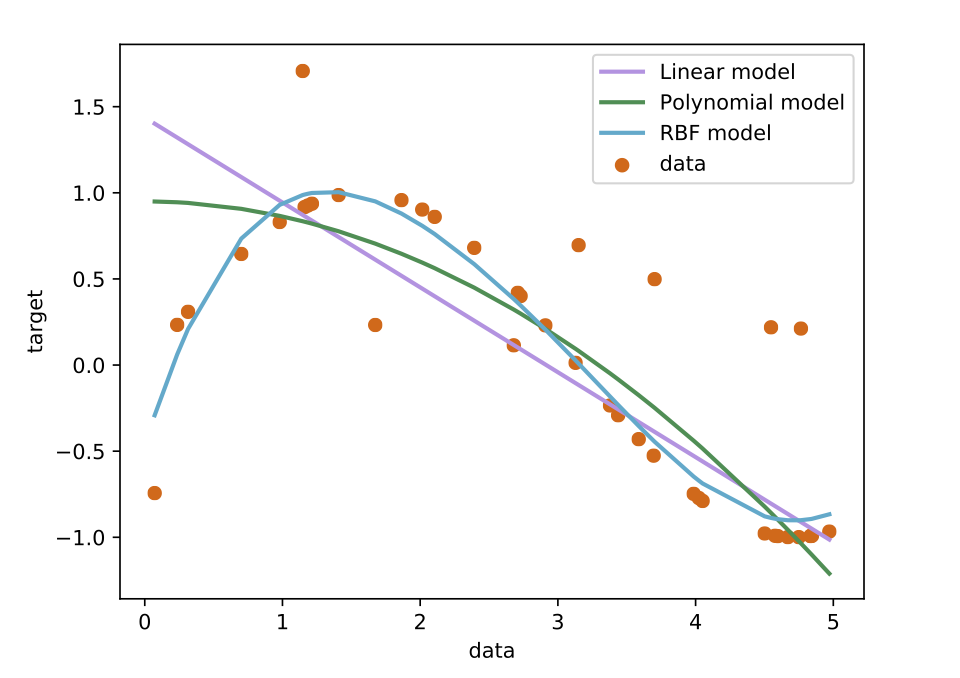 |
| Künstliche neuronale Netze bilden Synapsen und Nervenzellen (Neuronen) im Gehirn nach. Kantengewichte bestimmen über die "Anregung" der Neuronen. | Beim Boosting wird in jeder Iteration aus dem Fehler des vorherigen Durchlaufs gelernt. Anschließend werden die generierten Entscheidungsbäume addiert. | Bei der Support Vector Regression nähert sich das Modell dem Datenverlauf an. Dabei kann die Berechnungsmethode vom Anwender bestimmt werden. |
Evaluation
Wir haben uns auch mit verschiedenen Möglichkeiten der Evaluation und einzelner Kriterien, wie z.B. Mean Squared Error oder R-squared auseinandergesetzt.
 |
 |
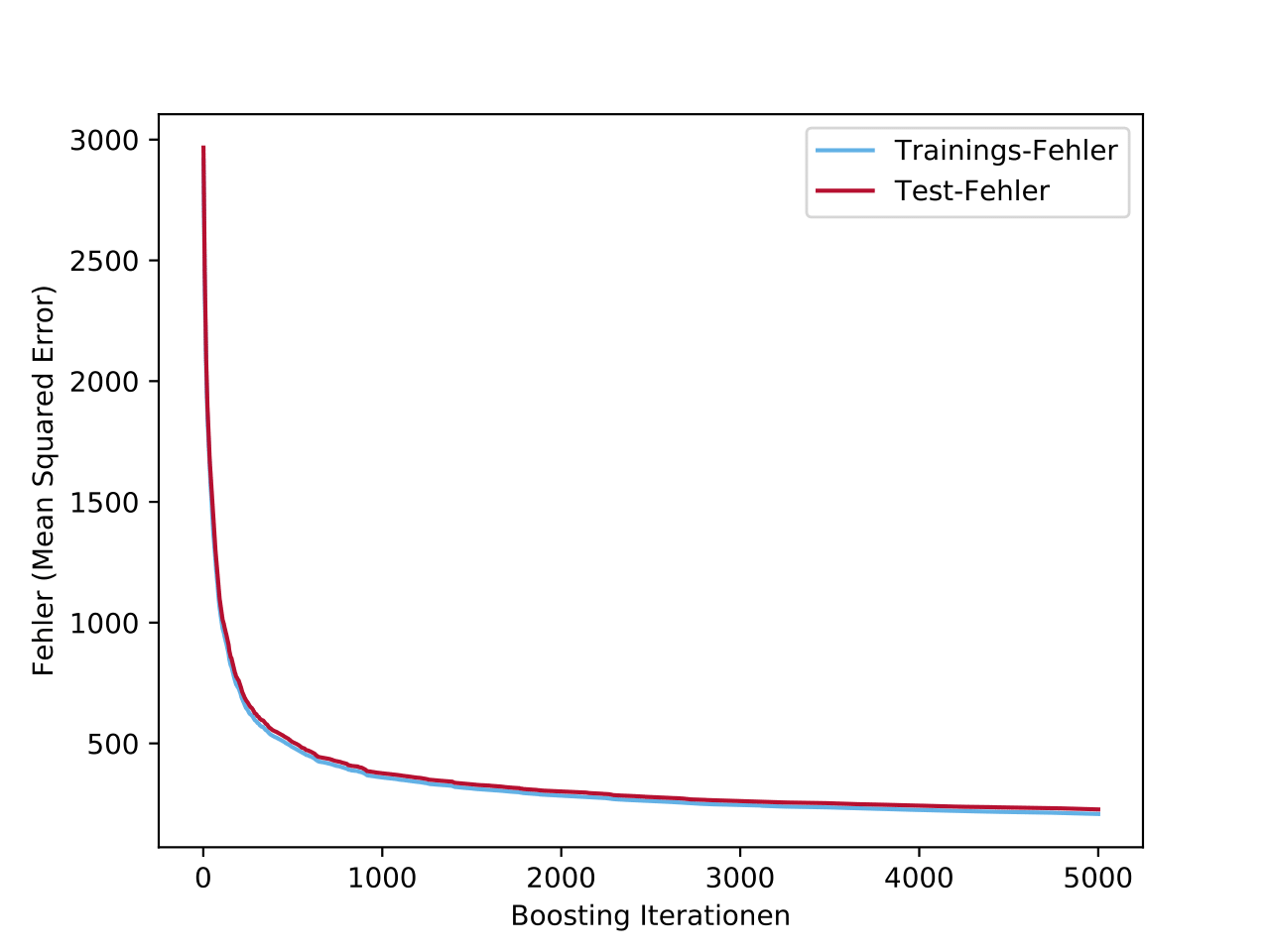 |
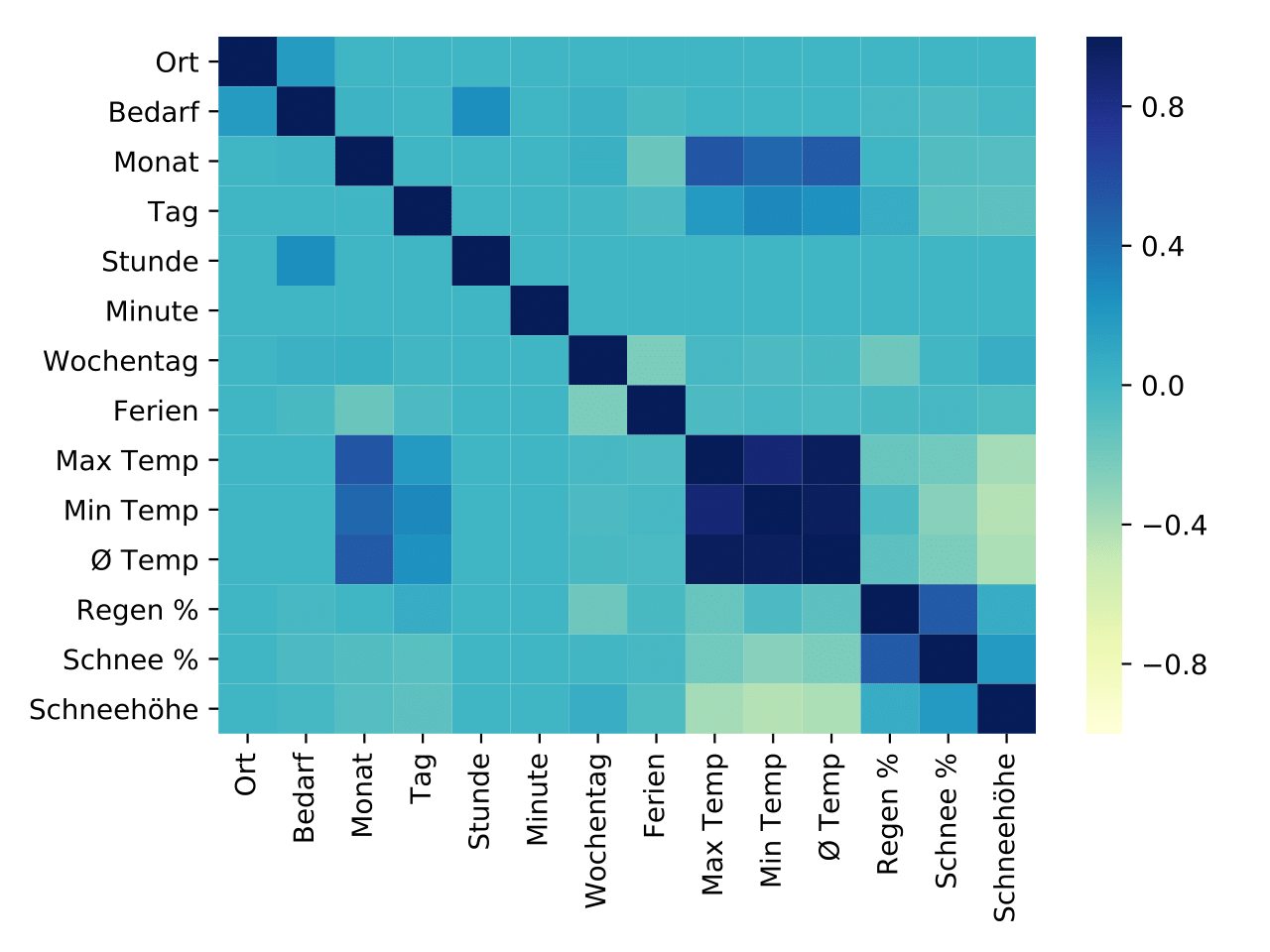
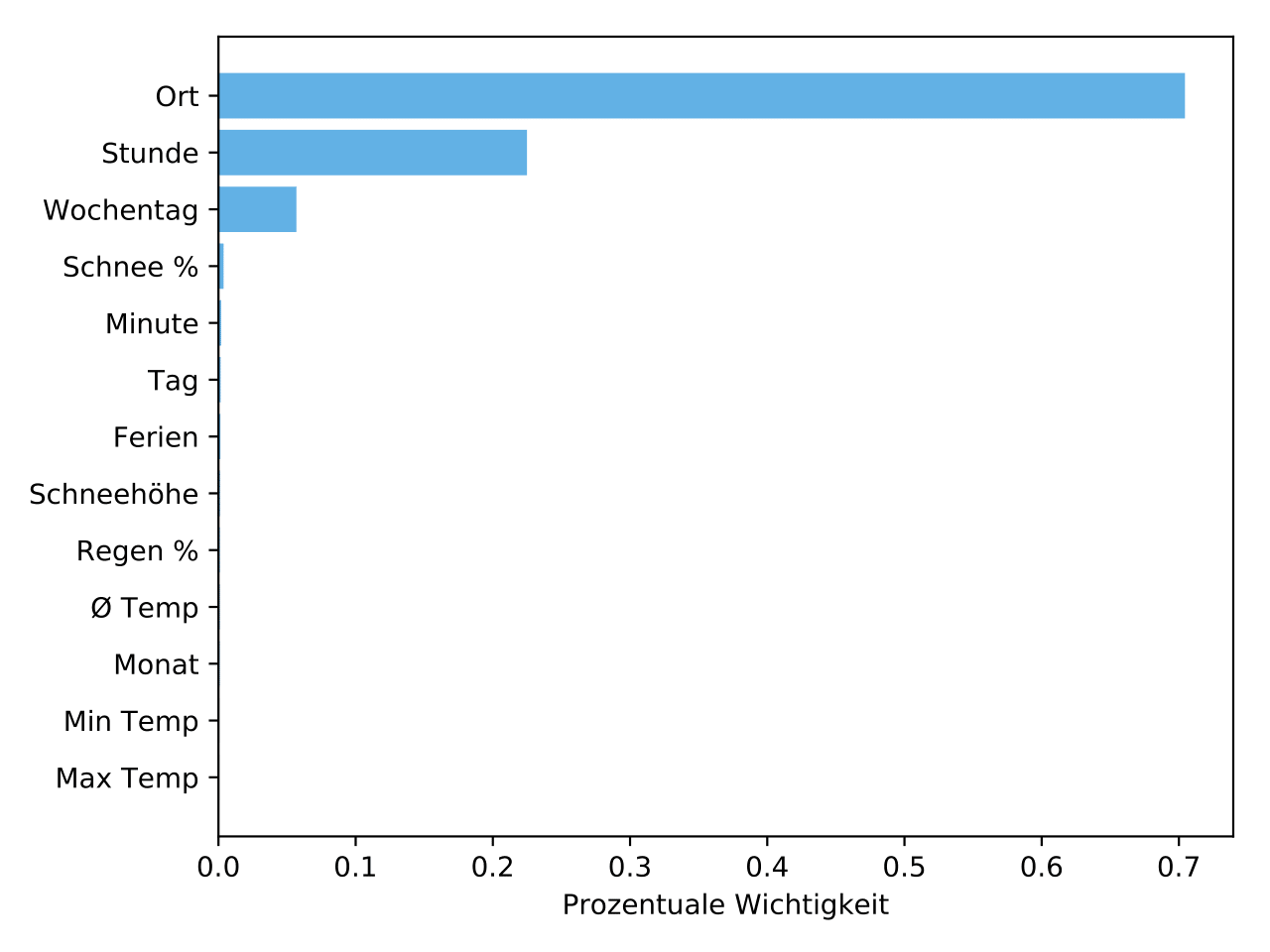
| Korrelationen der einzelnen Features des Taxi-Datensatzes, kombiniert mit Wetter- und Feiertagsdaten. Es fallen z.B. die logische Korrelation zwischen Monat und Temperatur auf, aber auch zwischen der Zielvariablen Bedarf und dem Abfahrtsort. | Nachdem ein Gradient-Boosting-Modell (mit Bäumen) trainiert wurde, lässt sich die Relevanz der einzelnen Features bezüglich der Ausgabe darstellen. Viele der Features sind zu vernachlässigen und könnten in zukünftigen Iterationen möglicherweise komplett entfallen. Dabei ist es aber auch interessant zu sehen, genau welche Features ausreichen, um die beste Vorhersage treffen zu können. | Der Fehlerverlauf des finalen Gradient-Boosting-Modells. Dabei wird zwischen dem Fehler auf den Daten, auf dem das Modell trainiert wurde und auf den Testdaten unterschieden. Durch die im Modell sehr gering gestellte Lernrate wird tatsächlich viel Overfitting vermieden (geringer Abstand zwischen Trainings- und Testfehler). |